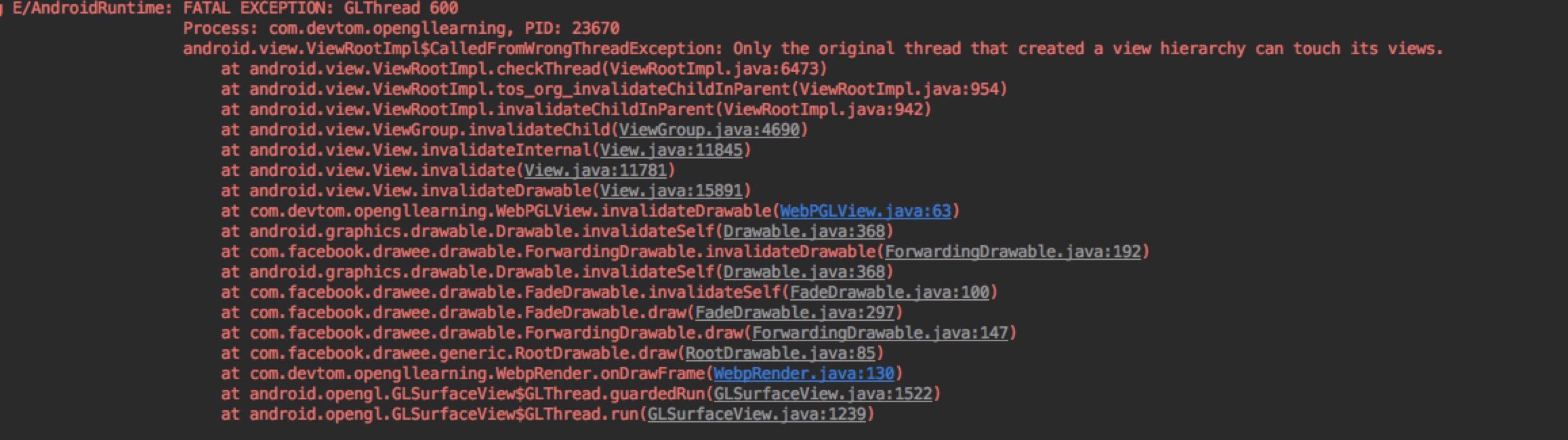
在AS 3.0,使用freeline的过程中,如果使用了databinding,在增量编译资源的文件的时候总是会报错,
提示的内容如下:
DataBindingInfo.java:5: 错误: 找不到符号。
首先来看一下这个 DataBindingInfo.java 中到底有些什么内容。
在使用freeline的项目中我们可以找到app/build/freeline/freeline-databinding/app/xxxxxxxxx/java/android/databinding/layouts/DatabindingInfo.java
这个类的内容如下:
|
|
这个类的内容十分的简单,一个叫DataBindingInfo 的类,使用了 一个叫 BindingBuildInfo的注解,这个注解里面有一些其他的属性,但是问题就是处在这个属性上面,我们可以直接在AS中搜索一下 BindingBuildInfo 这个注解。你会看到下面这个代码。
|
|
是不是一看知道问题在哪里了,BindingBuildInfo 这个注解里面根本都没有除了buildId之外的其他属性,如果在生成的类上面给这个注解强行加上这些属性,自然就报了找不到符号了。问题找到了那么我们需要找到这个 DataBindingInfo 类是怎么生成的。
在freeline当中有一个模块叫做freeline-databinding-cli,我们从这个模块里面入手,这个模块里面的代码很简单,这个模块生成了一个叫做databinding-cli.jar的jar文件,这个jar文件里面包含了一个main 方法,就是jar包的入口了。
然后直接查看类名ExportDataBindingInfo ,就很容易猜到 DataBindingInfo 是通过这个类生成的,我们进入到
DataBindingHelper.getLayoutXmlProcessor().writeInfoClass(sdkDirectory, outputDirectory, null, true, true);
这个方法最终会进入 LayoutXmlProcessor 的 writeInfoClass 方法,LayoutXmlProcessor 在com.databinding.tool这个包当中,这个包是通过gradle引入的,在freeline 当中,如果是使用java 8 ,这个包的版本是2.2.0,如果使用Java7,这个版本是2.1.3, 在这里就以java7为例说明。
在LayoutXmlProcessor当中,writeInfoClass的代码如下:
|
|
从中不难发现在生成这个类的时候,LayoutXmlProcessor自动的添加上了这些属性。
既然这是databinding版本的问题那么可以在build.gradle 文件的dataBinding 节点设置version 来改变databinding 的版本问题.
但是这个设定只是解决了databinidng compiler的版本,而 BindingBuildInfo 的版本却是我们在项目中gradle 插件的版本决定的,也就是项目根目录下面build.gradle 的 com.android.tools.build:gradle 版本号决定。
因此这里只改模块中databinding 编译的版本号也无法通过编译(需要查看databinidng 编译器的编译的源码查看 BindingBuildInfo 到底用的那个文件)需要同时修改想项目插件的版本,我想很多人应该都把AS 升级到了3.0,那么这里是无法使用2.0版本的gradle插件的。
那么这里的话就只能修改freeLine中compiler的版本的了,那么这之后项目中依赖的compilerCommon版本和freeline当中的一样了,
除此之外ExportDataBinding 中移除了writeClassInfo 方法,所以代码修改如下
|
|
但是修改了之后项目通过了,但是运行仍然会崩溃,还需要继续学习研究。